
In the previous post Two Statisticians in a Battlefield, we discussed the importance of reporting a spread in addition to an average when describing data. In this post we look at three specific notions of spread. They are measures that indicate the “range” of the data. First, look at the following three statements:
- The annual household incomes in the United States range from under $10,000 to $7.8 billion.
- The middle 50% of the annual household incomes in the United States range from $25,000 to $90,000.
- The birth weight of European baby girls ranges from 5.4 pounds to 9.1 pounds (mean minus 2 standard deviations to mean plus 2 standard deviations).
All three statements describe the range of the data in questions. Each can be interpreted as a measure of spread since each statement indicates how spread out the data measurements are.
__________________________________________________________
1. The Range
The first statement is related to the notion of spread called the range, which is calculated as:
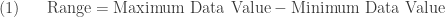
Note that the range as calculated in 
Figure 1

The range is a measure of spread since the larger this numerical summary, the more dispersed the data (i.e. the data are more scattered within the interval of “min to max”). However, the range is not very informative. It is calculated using the two data values that are, in this case, outliers. Because the range is influenced by extreme data values (i.e. outliers), it is not used often and is usually not emphasized. It is given here to provide a contrast to the other measures of spread.
__________________________________________________________
2. Interquartile Range
The interval described in the second statement is the more stable part of the income scale. It does not contain outliers such as Bill Gates and Warren Buffet. It also does not contain the households in extreme poverty. As a result, the interval of $25,000 to $90,000 describes the “range” of household incomes that are more representative of the working families in the United States.
The measure of spread at work here is called the interquartile range (IQR), which is based on the numerical summary called the 5-number summary, as indicated in 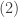

Figure 2

As demonstrated in Figure 2, the 5-number summary breaks up the data range into 4 quarters. Thus the interval from the first quartile (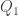


Figure 3

The IQR is the length of the interval from
__________________________________________________________
3. Standard Deviation
The third statement also presents a “range” to describe the spread of the data (in this case birth weights in pounds of girls of European descent). We will see that the interval of 5.4 pounds to 9.1 pounds covers approximately 95% of the baby girls in this ethnic group.
The measure of spread at work here is called standard deviation. It is a numerical summary that measures how far a typical data value deviates from the mean. Standard deviation is usually used with data that are symmetric.
The information in the third statement is found in this oneline article. The source data are from this table and are repeated below.

The third statement at the beginning tells us that birth weights of girls of this ethnic background can range from 5.4 pounds to 9.1 pounds. The interval spans two standard deviations from either side of the mean. That is, the value of 5.4 pounds is two standard deviations below the mean of 7.25 pounds and the value of 9.1 pounds is two standard deviations above the mean.

There certainly are babies with birth weights 9.1 pounds and below 5.4 pounds. So what is the proportion of babies that fall within this range?
We assume that the birth weights of babies in a large enough sample follow a normal bell curve. The standard deviation has a special interpretation if the data follow a normal distribution. In a normal bell curve, about 68% of the data are one standard deviation away from the mean (both below and above). About 95% of the data are two standard deviations away from the mean (both below and above). About 99.7% of the data are three standard deviations away from the mean (both below and above). With respect to the birth weights of baby girls with European descent, we have the following bell curve.
Figure 4

__________________________________________________________
Remark
The three measures of spread discussed here all try to describe the spread of the data by presenting a “range”. The first one, called the range, is not useful since the min and the max can be outliers. The median (as a center) and the interquartile (as a spread) are typically used to describe skewed distributions. The mean (as a center) and the standard deviation (as a spread) are typically used to describe data distributions that have no outliers and are symmetric.
__________________________________________________________
Related Blog Posts
For more information about resistant numerical summaries, go to the following blog posts:
When Bill Gates Walks into a Bar
For more a detailed discussion of the measures of spread discussed here, go to the following blog post:
Looking at LA Rainfall Data
__________________________________________________________
Reference
- Moore. D. S., Essential Statistics, W. H. Freeman and Company, New York, 2010
- Moore. D. S., McCabe G. P., Craig B. A., Introduction to the Practice of Statistics, 6th ed., W. H. Freeman and Company, New York, 2009
